WHAT IS WEB CRAWLING
I don’t think I would be able to write this blog. I have got no idea about the topic. Oh wait! Maybe I can refer to my best friend. Let’s google it. Now look at this. Google searched 7,160,000 results in just 0.11 seconds! This is amazing. Wonder how it works so fast. I will tell you. The trick behind all this is Web Crawlers.
“A web crawler or web spider or web robot is a computer program that browses the World Wide Web in a methodical, automated manner or in an orderly fashion.”[Wikipedia]. Or you can simply say it is software used to crawls a web page and create its own up-to-date copy of that web site. In fact, the name web crawler or spider is inspired by the spider itself. A web crawler crawls across web pages just as the way a spider crawls all over a place. You just need to give it a base URL or seed to start its work. Then http request of that page is made to World Wide Web so as to retrieve the information on that page. After that links on the page are extracted and indexed in crawl frontier. Crawler then visits these URLs and crawls through them in the same way. The recursive visits to a frontier URL is made according to certain policies.
Every search engine uses its own web crawler to keep a copy of all sources on internet. Slurp is web crawler used by Yahoo! while Google uses one called Googlebot. They regularly crawls web pages and give away the information to an indexer. Location and content of these pages are added to index database in alphabetical order. Whenever you makes query to google, it refers to its database which is similar to an index at the back of a book. It tells which word can be found on which page. Related document to the query are retrieved and a snippet for each search result is generated. In this way a search engine is able to return you the results in fraction of second.
USING A WEB CRAWLER
Many web crawler for different OS are freely available on internet. If you use Mac OS you can download SiteCrawler or Blue Crab. For Ubuntu Harvestman or Httrack cab be good options. Or use WebSPHINX or Web Reaper for Windows.
We chose to work using Win Web Crawler – a powerful utility available for Windows.
Now let us explore some of its functions. Select New from toolbar to start crawling

Win Web Crawler gives us 3 options to crawl the internet.
1) SEARCH ENGINES : Searching for a keyword in a list of search engines.
i) Select the option search engine in the General tab.
ii) For searching a keyword “System Management” in google, click on Keyword Generator.

iii) Type System Management below Generated Keywords:

iv) Now select one or more search engines of your choice:

v) Select the destination in which you want to save the results. Click ok.
Wuholla......We made our Crawler work like a search engine.......
2) WEBSITE/DIRS : Indexing the various options in a particular website.
i) Give the name of website you want to crawl

ii) Specify the destination.
iii) You can choose to save data line-by-line or in cvs format where each line is separated by commas.
iv) Choose if you want to extract Meta tags and external URLs, i.e. URLs which are outside the given site
v) Click on OK.
PROCESS :
You can see the processes being completed by the crawler with their details.

RESULT :
A list of extracted URLs is generated for you.

3) URLs FROM FILE : Indexing the contents of all the URLs present in a file
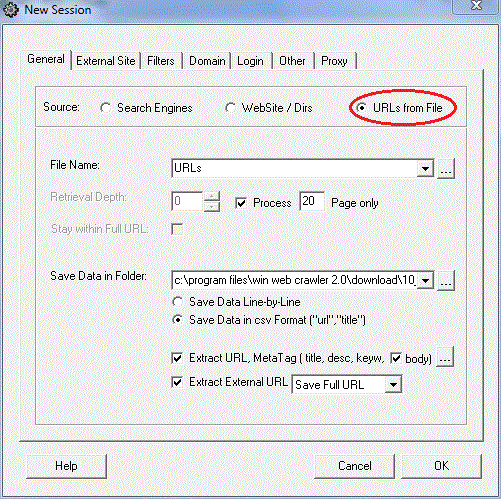
i) Select the .txt file which has the URL’s you want to crawl.
ii) Select the crawl depth.
iii) Select the destination folder and click OK.
RESULT :

** the file URL.txt has the URL’s http://www.iiitd.ac.in and http://www.google.com. **
DO IT YOURSELF
How interesting would it be if I tell you that you can create your own web crawler. Many programming languages such as python, java, perl, etc can be used. Linux terminal also provides some commands to achieve this task. Wget is one such command that we have used to create WebCrawl.
##Script for WebCrawl
echo "Welcome to WebCrawl"
echo -n "Enter the number of urls you want to search: "read n
rm input.txt
for ((i= 1;i<=$n;i++))
do
echo -n "http://www."
read url
echo $url | sed 's/^/http:\/\/www\./g' >> input.txt
done
echo -n "Enter recursion depth: "
read dep
wget -r -H -k -p --level=$dep --wait=2 -i input.txt
##End of Script
You need to copy this script and save as WebCrawl.sh. Then run it using your Linux Ubuntu terminal.
How to use WebCrawl:
i) Enter the number of sites you want to crawl.
ii) Then enter the URLs of all those sites.
iii) Then give the recursion depth.

WebCrawl is at work…

All data is stored in folders on your machine.

Before reading this post you might have wondered what a web crawler is all about. But believe me web crawlers are fun to use and to learn about. And the part which is most fun is making your own crawler. Remember you need to achieve three goals with your crawler :
1. Retrieve a document and mark it as done.
2. Extract the connected URLs.
3. Index your result.
After completing the criteria you can also make a lot of interesting search applications yourself.
This post is submitted by:
Deepika Moorjani (2011041)
Nitika Jain (2011073)
Hi Deepika.....
ReplyDeleteIt was really helpful for me and am interested to do this project...
I Need source code for this web crawler will you please Help me,......
send me the code through balu.jagua1991@gmail.com